Advent of code - Day 3
Part 1
Read in data into a pandas dataframe.
import pandas as pd
import numpy as np
df = pd.read_csv('day3input.txt',delimiter=' ', skip_blank_lines=True,header=None)
df.head()
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | #1 | @ | 387,801: | 11x22 |
| 1 | #2 | @ | 101,301: | 19x14 |
| 2 | #3 | @ | 472,755: | 11x16 |
| 3 | #4 | @ | 518,720: | 23x17 |
| 4 | #5 | @ | 481,939: | 29x20 |
- Strip column 2 of its trailing colon, split the column on the comma into x_space and y_space.
- Split column 3 into x_length and y_length by the ‘x’ inbetween the to values.
df['x_space'], df['y_space'] = df[2].str.strip(':').str.split(',',1).str
df['x_length'], df['y_length'] = df[3].str.split('x',1).str
df.head()
| 0 | 1 | 2 | 3 | x_space | y_space | x_length | y_length | |
|---|---|---|---|---|---|---|---|---|
| 0 | #1 | @ | 387,801: | 11x22 | 387 | 801 | 11 | 22 |
| 1 | #2 | @ | 101,301: | 19x14 | 101 | 301 | 19 | 14 |
| 2 | #3 | @ | 472,755: | 11x16 | 472 | 755 | 11 | 16 |
| 3 | #4 | @ | 518,720: | 23x17 | 518 | 720 | 23 | 17 |
| 4 | #5 | @ | 481,939: | 29x20 | 481 | 939 | 29 | 20 |
- Drop unnecessary columns
- Change datatypes to integers
df.drop(columns=[0,1,2,3],inplace=True)
df = df.astype(int)
df.head()
| x_space | y_space | x_length | y_length | |
|---|---|---|---|---|
| 0 | 387 | 801 | 11 | 22 |
| 1 | 101 | 301 | 19 | 14 |
| 2 | 472 | 755 | 11 | 16 |
| 3 | 518 | 720 | 23 | 17 |
| 4 | 481 | 939 | 29 | 20 |
Find max x and y coordinates for mapping out fabric.
max_x = df['x_space'].max() + df['x_length'].max()
max_y = df['y_space'].max() + df['y_length'].max()
print('Max x value : {}'.format(max_x))
print('Max y value : {}'.format(max_y))
Max x value : 1016
Max y value : 1012
Initialise array of zeros of dimensions (max_x, max_y) representing the fabric.
fabric = np.zeros((max_x,max_y))
For each row in the dataframe:
- Read values for x, y, x_length and y_length
- Initialize array of ones of dimensions (x_length, y_length) representing the size of the claim.
- Add the claim array onto the fabric array at the corresponding coordinates
for i in range(len(df)):
x, y, x_length, y_length = df.loc[i,:]
claim = np.ones((x_length, y_length))
fabric[x:x+x_length, y:y+y_length] += claim
Fabric representation and mapping example:
sample = np.zeros((5,5))
sample
array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
sample_claim = np.ones((2,3))
sample_claim
array([[1., 1., 1.],
[1., 1., 1.]])
sample[0:2, 1:4] += sample_claim
sample
array([[0., 1., 1., 1., 0.],
[0., 1., 1., 1., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
Find counts of overlapping claims.
unique, counts = np.unique(fabric,return_counts=True)
print(sorted(zip(unique, counts)))
[(0.0, 679490), (1.0, 233398), (2.0, 85755), (3.0, 22904), (4.0, 5526), (5.0, 931), (6.0, 172), (7.0, 16)]
Find total that is overlapping with at least one other claim.
total_double_matched = counts[2:].sum()
print('Total double matched : {}'.format(total_double_matched))
Total double matched : 115304
Part 2 - Find the only claim with no overlap
We already have an array holding the fabric, with all the claims added in the correct place.
import matplotlib.pyplot as plt
plt.figure(figsize=(12,12))
plt.title('Visual representation of fabric')
plt.xlabel('x-coordinates')
plt.ylabel('y-coordinates')
plt.imshow(fabric)
plt.colorbar()
plt.show()
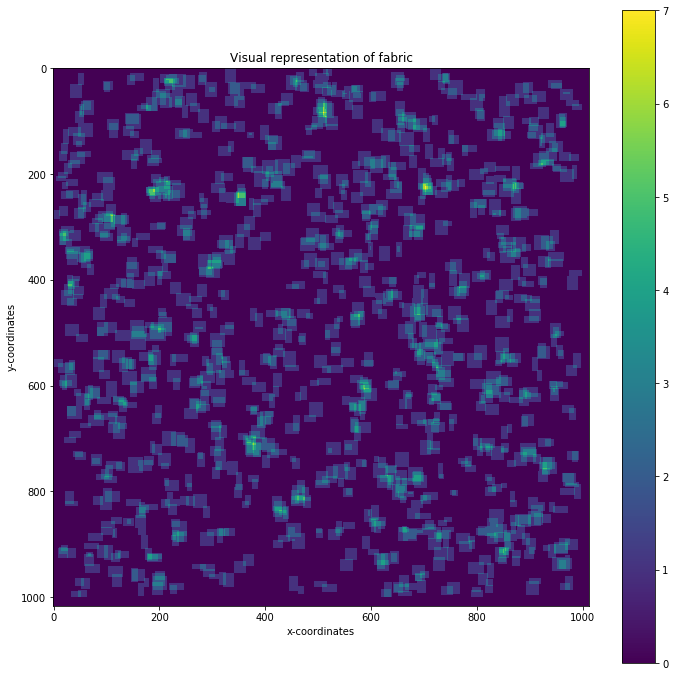
So to find the claim that does not overlap we need to loop through the claims again, checking whether the claim (array of ones) is equal to the fabric at the coordinates of the claim.
for i in range(len(df)):
x, y, x_length, y_length = df.loc[i,:]
claim = np.ones((x_length, y_length))
if np.array_equal(fabric[x:x+x_length, y:y+y_length], claim):
print('Thats the one! :\n', df.loc[i,:])
Thats the one! :
x_space 336
y_space 615
x_length 28
y_length 21
Name: 274, dtype: int64
Name : 274 is the entry we are looking for, my answer is 275 because we deleted the index column earlier and pandas dataframes index from 0 and not 1.